by Dany Hoter
Hello, welcome back. This is module three from the course about analyzing and visualizing data in Excel. In this module I will introduce you to queries in Excel that are done using a technology that was previous to 2016, which I’m using, was known as Power Query.
If you’re using Excel 2013, or even Excel 2010, you’ll be able to follow it and see the functionality that I am going to use here.
You’ll see it as functionality of the Power Query add-in in Excel.
In 2016 what we did is include all this functionality in Excel, and now there is no add-in anymore. There’s no Power Query add-in.
So you’ll see that the same functionality is now folded into the regular ribbons of Excel. And it’s there side by side with older functionality to import data in Excel.
Further down in the next versions of Excel we plan to make this technology that came from Power Query, it is now not called Power Query any more, the default technology to import data. But for now it’s there side by side and I’m gonna use it exclusively to bring data into Excel.
My first example in bringing data from using the query will be very simple.
I will just be importing a single flat CSV file, and make it into my model. This table has everything I need, not necessarily ready in the shape and the form that I need it but I will form it and shape it using the query.
So let’s start.
We switch to Excel.
In the data ribbon, there at top in the ribbon, you see there’s an area here what we call a chunk that the title is Get and Transform.
This is where you are looking what was previously, or is still in 2013, known as the Power Query functionality. And most of it is under here, the new query.
Here, you start your queries. Power Query is a technology that is designed to bring the data into Excel.
It can bring data into the Excel grid as tables, and you could then use them for any use that you want in Excel. Or it can bring data directly into the Excel data model that was introduced in the previous part of this course. And it can actually bring data to both, which I would not recommend you to do, but if you want to it’s possible.
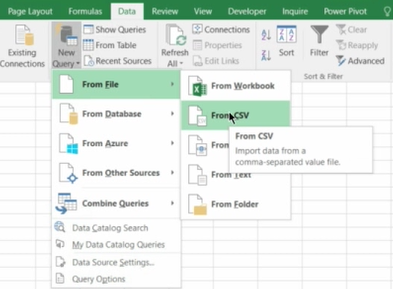
Now, first thing I need to do is to pick the source that I want to use.
What kind of source is it? It’s a file.
What file is it? It’s a CSV file.
So I would say I want to query, to create a new query from CSV file.
Now, I’m gonna browse for the file.
The file is here and it’s called onetable.csv and I just double click. And now what I will see next is the query editor, so this is a environment in which I am going to enhance the query, create the query and then I can save the query, and every time I need I can write it again to refresh the data to bring the data from the same source again.
So here I see the data.
Looks pretty good to me.
But there’s still a few things which I need to do in order to prepare this data.
So first of all there are some columns which I don’t need.
So let’s say I don’t need the district, so I can just go right-click and remove it. This one here, maybe also I don’t want it. I can also go and remove it.
So I can decide which columns do I want to leave as they are or otherwise others that I can remove.
Let’s watch now the column named city.
You see that this formative as a city colon comma three. State comma the country which is USA for everyone. I also have a separate columns for the state and for the country.
So, actually, I don’t need all this superfluous data. I don’t need it both in the city and in the other column, so I would like to actually, leave here just the city.
So, what I can do, I can select this column and then I use, from the ribbon this tool, from the transformations available for me, I will use split columns.
So I say yes, I want to split it be using the delimiter, the delimiter is a comma.
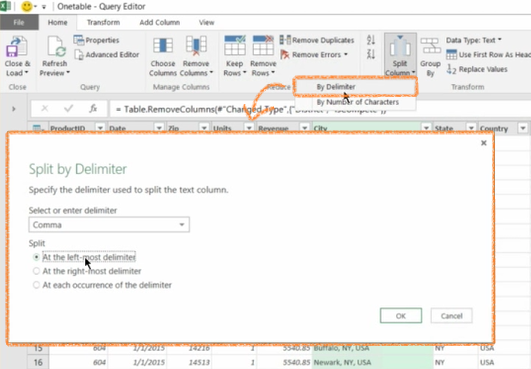
I want just to use it once, so I say the left most delimiter, click OK. And the result is that actually now I have two columns. Column 1 called City.1 and Column 2 called City.2.
City.2 is the one I don’t need, so I will remove it.
City.1, I can double-click the header and just rename it to be just City.
So I’m doing a simple a series of simple steps to make this data ready for its purpose to be used later as the basis for my pivot tables, so far nothing really fancy.
Now another thing is that the state, I actually only have data from two states here, New York and Texas, but the state comes as abbreviation. And I want this column to have the full name of the state. So I can do right-click and say Replace Values.
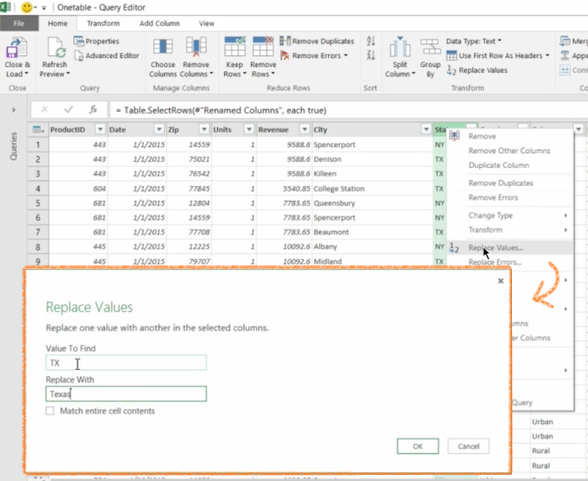
And I can do something do very simple, I say, when it’s TX, I want it to show Texas.
And here it goes.
And again, I will say Replace Values when it says NY, I want it to say New York. My mistake there, all right.
Now this looks like very manual work, I’m just going to replace.
But the good thing is if you look at the right side here, you see here the query settings here, one is that name of the query.
And I can change this to be, let’s say, I don’t know, SavesData. Because this name here will become eventually the name of the table in the model once I import it.
So I want to give it a nicer name than just OneTable. And then below that I have a list of applied steps.
This is actually each one of them is one of the steps that I did while I working on this data.
So I removed columns and each time I click on one of them, I actually see the way the data looks after the step.
So I can go and retrace me step and see exactly where I was and how did it look.
This series of steps is actually creating some kind of a script that will be saved as part of the query.
Next time, I will run the query by clicking refresh on the table that I will create.
This series of steps will be repeated, starting from the source from exactly the location of the source when I picked it up, and going forward with all the steps.
And this is why I’m not really worried about manual steps and repeating them because I do it once and then they will be repeated again and again for me.
So here we saw a list of very simple steps, later on we’re gonna see there’s a few more parts about using queries.
And we’re gonna see more sophisticated steps they can apply.
Now I’m done with preparing the data. It looks ready to me, so it can go and from here I have Close and Load or Close and Load To.
Close and Load To enables me to choose the target for this data when it’s gonna be and there’s two parts to it.
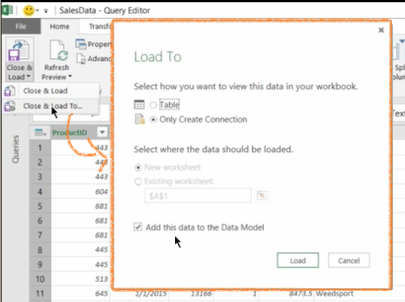
One is, do I want to see it in the workbook itself? So do I want it to create a table for me or I only want it as a connection that then can be used for refresh and so on? So in this case I leave it as the default for me here, Only Create Connection.
The second part is about this checkbox, do I want it in the data model (add this data to the data model)?
The fact the default comes this way is because I configured before. I can configure it this will be different for me. Because this is the way usually I do it. But anyhow, you see here the two parts and now I don’t need to change anything, I can click Load.
And on the right side you see the progress of this query and it says that they have 33,000 and something loaded. When I hover over it I see a preview of the data and we don’t see any of the data because it’s actually in the data model, this is where I asked it to go to the data model.
But I can go in here, insert a pivot table, again the default for 2016 is use this workbook from the data model.
If you are on previous version, I would recommend it’s much easier to go to the Powerpivot add-in and create the pivot table from there. You can do it from Excel but it will take you about eight clicks instead of one.
And now you see on the right side that actually the field is for the pivot. It has only one table with everything in it because [INAUDIBLE].
And you see here that I have the revenue which I can click on. I have the countries. Country is not very useful because it’s all from one country so, I take it out. State, within State, the City.
So I’m having pivot off all the cities. And I can actually go and create a pivot based on this data.
So that will conclude this part, in which we saw the first example of using a query.
Previously known as Power Query in Excel 2016 to bring flat CSV file.
Applying some steps to it and bringing into the model and then creating a pivot table from it.
In the next modules we’ll see building of more complex data models also using queries. And then eventually we’ll also go dive into Docs and create more sophisticated logic within these data models. So bye for now and see you in the next one.
Assessment:
- Which city in Texas has the most total sales (highest revenue)?
- What three data pre-processing steps can be done in the Query Editor?
- Which district has the most total sales (highest revenue)?
- Which three file formats are valid input for queries From File?
- Using the Replace Values step, how many distinct values can be replaced at a time?
- Where are data pre-processing steps recorded in the Query Editor?
- Given what you discovered in Question 3, does the same pattern hold true in each of the individual districts?
- Which city in New York has the least total sales (lowest revenue)?
- What are two ways of loading data into Excel by using queries in Excel 2016?
- How many cities in the State of New York have sales (Revenue)? (Hint: Distinct Count aggregation might be useful)
- Which district has the least total sales (lowest revenue)?